
JavaScript Fundamentals
7 min read
When I first started programming with JavaScript, I jumped straight into Angular, and then React. These frameworks and libraries are great, allowing us to build web apps pretty quickly, without really needing to know how JavaScript works. If you need to get the job done quickly, then getting to grips with something like React is enough work in itself to keep you busy.
Once I felt like I understood React, I wanted to go back and get a better understanding of how JavaScript works at its core. I felt like I knew bits and pieces of it, but wanted to come up with a solid mental model that pieces everything together.
After watching some YouTube videos and reading around, here’s my summary.
Thread of execution
- JS is a single-threaded language.
- A thread is a single sequential flow of control.
- It has a call stack and memory.
- In essence, this means that JS is a synchronous language. It does however, have some asynchronous capabilities in a run-time environment through web APIs and Node.

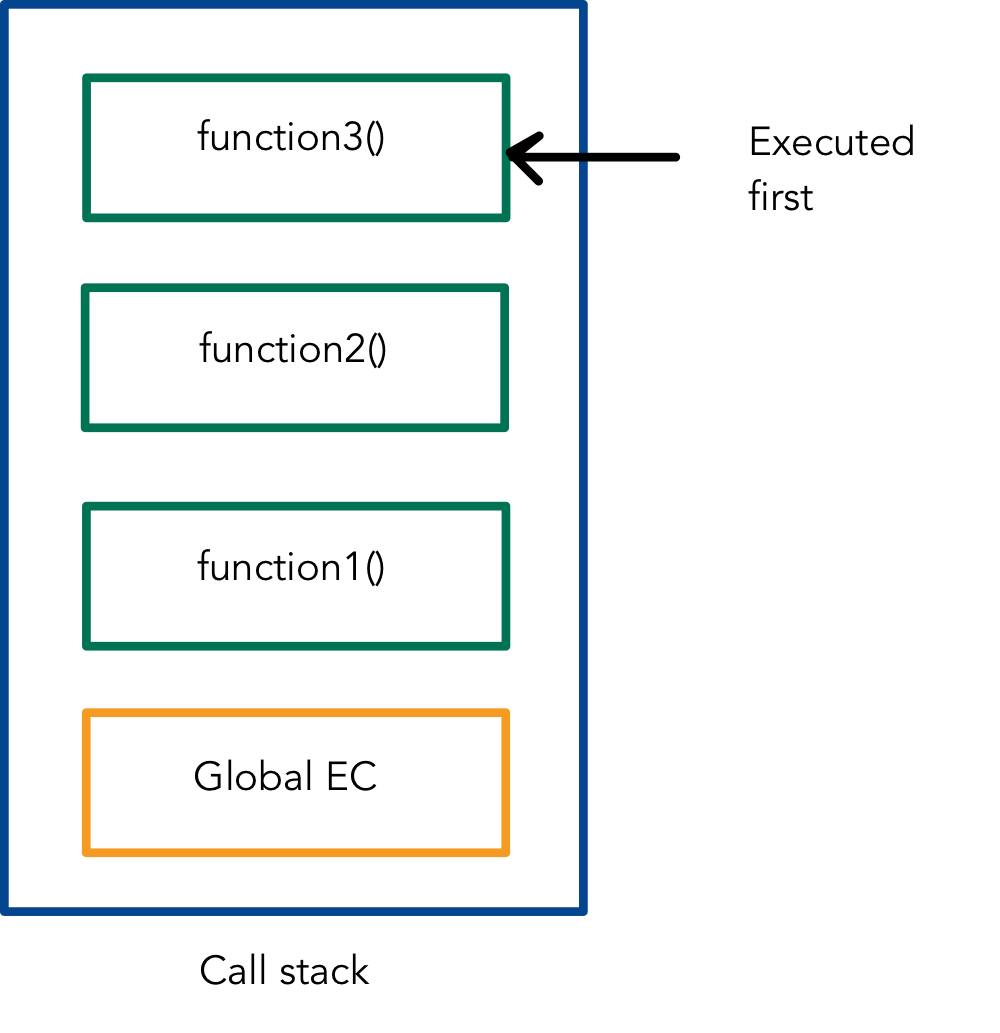
Call stack
- Stack of functions to be executed. A stack is a data structure. It adheres to LIFO (last in, first out).
- Operations are pushed on to the stack, and popped off once completed.
- The JS call stack manages execution contexts (more below).
- JS has a global execution context that underpins the call stack.
- Note: This is shown as “anonymous” in the browser dev tools, within the call stack tool.
- If we had a function1, that calls function2, that calls function3, the call stack would look like this.
Execution context
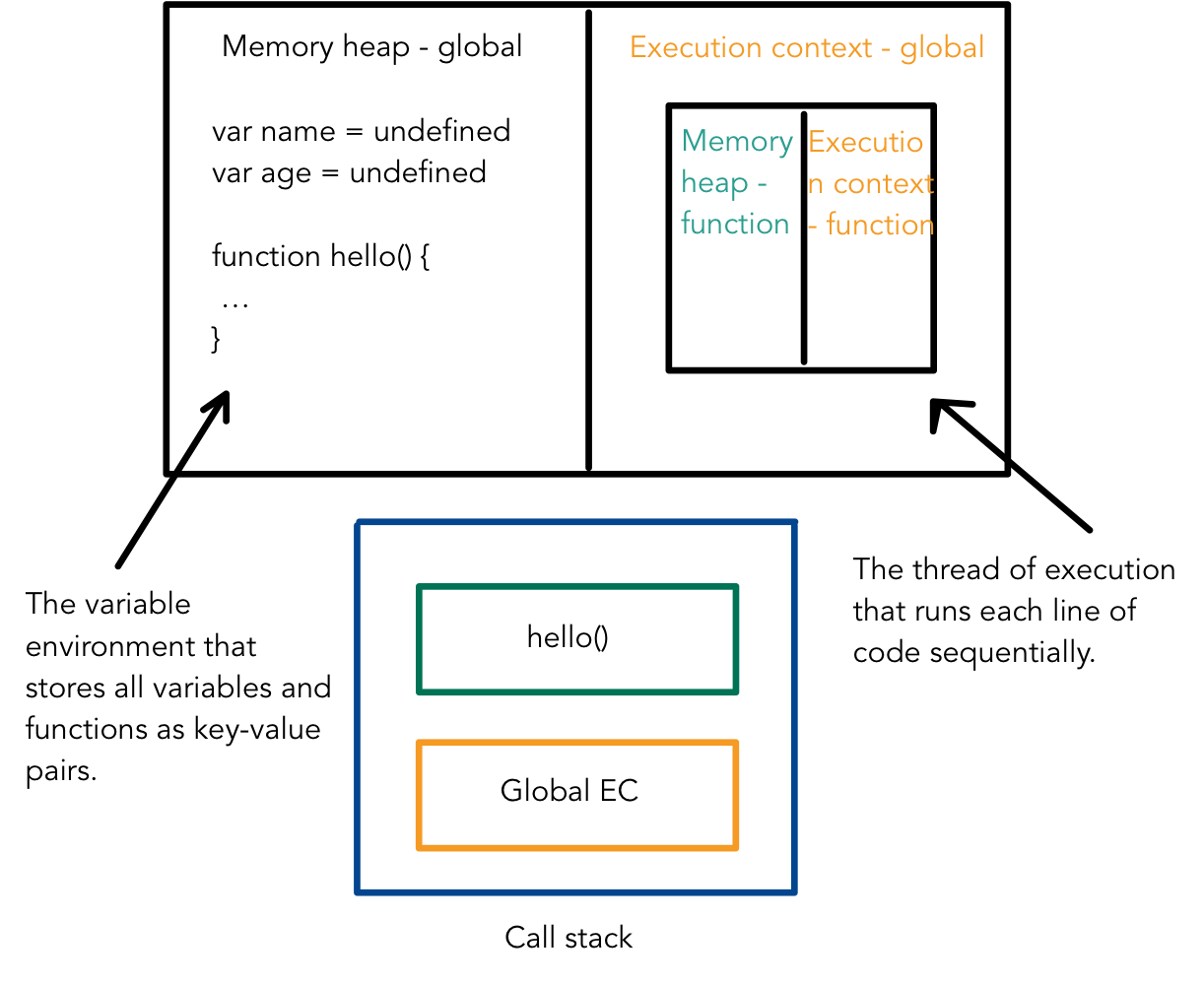
- The execution context is an environment created to handle the transformation and execution of JavaScript code.
- It contains the currently running code and everything that aids its execution.
- There exists, a global execution context, and a function execution context for every function invoked.
- There are 2 phases in the execution context, the memory creation phase, and the execution phase.
- Think about it as passing over your code twice, first for allocating memory, then to actually run the code.
- Memory creation phase:
- Creates the global object. In the browser, this is
window. In Node, this isglobal. - Creates the
thisobject and bind it to the global object. - Sets up the memory heap for storing variables and function references.
- Stores functions and variables (
var,const,let) in the global execution context and sets them toundefined. Note that the whole function definition is stored.
- Creates the global object. In the browser, this is
- Execution phase:
- Executes code line by line.
- Creates a new execution context for each function call.
Hoisting
- As we saw above,
varand functions are hoisted. They are allocated memory during the memory creation phase.- This means they are accessible in the global object, and can be called before they are assigned.
varwill beundefinedif called before it is assigned.
letandconstare block scoped. They are still hoisted, but are not accessible until it’s assigned in the execution phase.- Stored in the temporal dead zone before they are assigned.
Asynchronous JavaScript
- There are web API and Node functions that allow us to run JavaScript in an asynchronous manner.
- If we take the example of the
setTimeout()function (this is from the web API, not JS!) for instance, this takes a callback function which is executed after a set time period. - This callback function is added to a “task queue”, which is added back to the JS call stack as part of the event loop.
- Asynchronous functions that return promises are added to a separate “microtask” queue, that has a higher priority over the task queue, when callback functions are added back to the call stack.
- These queues are FIFO, first-in, first-out.
- The event loop monitors the call stack and callback queues. If the call stack is empty, the event loop takes the first event from the queue and pushes it onto the call stack.
- A single iteration is called a tick in the event loop.
- What this means is that
setTimeoutadds your callback function to the queue after X amount of time. It doesn’t mean your callback function will be executed in X amount of time.- If there are other events in the event loop queue, these will need to be completed first.

Memory storage
- Higher level languages like JS and Python automatically allocates memory when objects are created and frees it when they are not used anymore. This process is called garbage collection.
- Primitive types are stored directly on the stack, where it is directly accessed. These are static data i.e.allocated a fixed amount of memory that doesn’t change.
- String, number, boolean, null, undefined, symbol, bigint
- Reference types are stored in the heap and accessed by reference. These are objects which can be amended, thus needing variable memory.
- Arrays, functions, objects
- An example of practical implications:
// When dealing with primitives
let animal = 'cat'
let says = 'meow'
let newAnimal = animal
console.log(newAnimal) // 'cat'
let newAnimal = 'dog'
console.log(newAnimal) // 'dog'
// When dealing with reference types
let pet = { animal: 'pig', says: 'oink' }
let newPet = pet
newPet.animal = 'chicken'
console.log(pet.animal) // 'chicken'
JavaScript engines, interpreting and compiling
- JS engine is a software component that optimises and executes JS code.
- Each browser uses a specific JS engine (generally written in C or C++).
- Firefox - SpiderMonkey. Created by the creator of JS, Brandon Eich. First engine ever created.
- Chrome - V8 Engine. Extremely fast and can run as a standalone. Also used by NodeJS runtime.
- Microsoft Edge - Chakra. Microsoft proprietary engine.
- Safari - JavaScriptCore. Other WebKit browsers also use this.
- JS is an interpreted language. Interpreted languages are interpreted line by line, and converted to machine code.
- Written to machine code and executed at the same time.
- Compiled languages are compiled directly to machine code, and then executed.
- Extra step of compilation, but subsequently has a fast run time. Interpreted languages are the opposite.
- Looking at the V8 engine:
- Source code that we write is sent to the parser. The parser checks the code line by line to ensure syntax is correct. If there’s an error, it stops.
- This then generates an abstract syntax tree (AST). Think of it like a JS DOM. It represents the code as a tree of nodes.
- The interpreter takes the AST and converts it to bytecode. Bytecode is an intermediate level of abstraction above machine code. We don’t convert to machine code directly because machine code is unique to the architecture of your machine (bytecode works across all machines).
- Bytecode also allows for optimisation. Most engines use the Just In Time (JIT) compilation method for optimisation, which converts bytecode to machine code on the fly at run-time. This gives it access to specific dynamic runtime information.
- Note that AOT is Ahead of Time compilation. This is what compiled languages use where machine code is generated before run-time.
- Machine code is then run by the machine’s hardware.
References